Much like the rest of the software developers out there I’ve been following the recent advancements in the field of AI with great interest, and a bit of fear.
With large language models taking the world by storm, there has been a surge of hype surrounding the extent of their capabilities and their usefulness in our day to day lives.
I’ve always been a skeptic when it comes to new technologies, and being someone who tinkering with new tech, I set myself up with the challenge of building something practical using these tools to firstly learn about them but also to assess their usefulness.
So I did some research to identify a practical task to target my energy on.
In addition to their widely known usage in chatbot applications, here are some of the other practical use cases I came across:
- Sentiment analysis
- Example: analyse finance news headlines and content to predict market sentiment
- Customer feedback analysis
- Example: analyse customer feedback submitted via forms and other channels
- Summarization
- Example: News platforms can use large news articles into a few lines of text
- Zero-shot classification
- Example: This can be used by platforms for content moderation. By using prompting techniques, high-level categories like “hate speech”, “violence”, “safe” can be assigned to articles dynamically.
Initially I thought about creating a Q&A chatbot but quickly I realised that this is a very overdone concept (see here, here and here for a few examples).
So instead I thought about working on something simple and generic so that it can be applied to different use cases. I came across a few articles and online videos where the LLMs were trained to some private data, never before seen by the model, in order for them to be leveraged later on for sentiment analysis or zero-shot classification.
The Goal Link to heading
I looked through quite a few datasets and landed on a large collecton of data on Goodreads’ website, a platform for book lovers to find, discover and review books.
You can find the data collection here.
Here are some sample data from the collection (top 5 books sorted by highest average rating):
| book_id | cover_image_uri | book_title | book_details | num_pages | genres | num_reviews | average_rating |
|---|---|---|---|---|---|---|---|
| 1 |  | Harry Potter and the Half-Blood Prince | It is the middle of the summer, but there is an unseasonal mist pressing against the windowpanes. | 652 | [‘Fantasy’, ‘Young Adult’, ‘Fiction’, ‘Magic’, ‘Childrens’, ‘Audiobook’, ‘Adventure’] | 58398 | 4.58 |
| 2 |  | Harry Potter and the Order of the Phoenix | Harry Potter is about to start his fifth year at Hogw | 912 | [‘Young Adult’, ‘Fiction’, ‘Magic’, ‘Childrens’, ‘Audiobook’, ‘Adventure’, ‘Middle Grade’] | 64300 | 4.5 |
| 3 |  | Harry Potter and the Sorcerer’s Stone | Harry Potter has no idea how famous he is. That’s because he’s being raised by his miserable aunt | 309 | [‘Fantasy’, ‘Fiction’, ‘Young Adult’, ‘Magic’, ‘Childrens’, ‘Middle Grade’, ‘Audiobook’] | 163493 | 4.47 |
| 5 |  | Harry Potter and the Prisoner of Azkaban | Harry Potter, along with his best friends, Ron and Hermione, is about to start his third year at | 435 | [‘Fantasy’, ‘Fiction’, ‘Young Adult’, ‘Magic’, ‘Childrens’, ‘Middle Grade’, ‘Audiobook’] | 84959 | 4.58 |
| 6 |  | Harry Potter and the Goblet of Fire | It is the summer holidays and soon Harry Potter will be starting his fourth year at Hogwarts Scho | 734 | [‘Fantasy’, ‘Young Adult’, ‘Fiction’, ‘Magic’, ‘Childrens’, ‘Audiobook’, ‘Middle Grade’] | 69961 | 4.57 |
In this article i’m going to go through and describe the process of teaching an LLM to learn at least “some” new facts with this data collection in addition to sharing the final notebooks.
Overview of LLMs and GPT Link to heading
Large language models are a type of neural network and are trained on a large corpus of text. For example Llama 2, one of Meta’s open-source large language models, was trained on approx 10 Terrabytes of data found on the internet.
The idea is by exposing the model to a large amount of text, it can learn the patterns and structure of the language.
The task of the models are to predict the next word in a sentence given the previous words. They do this billions of times over the course of training.
Generative Pre-trained Transformer (GPT) series of models are the most recent advancements in the field of large language models, with the first GPT model developed by OpenAI in 2018. Initial GPT was trained on ~5GB of text data, GPT-2 was trained on ~40GB of text data, and GPT-3 was trained on ~570GB of text data.
GPT models so far have been trained on a large corpus of text data which produces what they call a “base model”. This base model is then fine-tuned on a smaller dataset to perform a specific task, such as question and answer.
One limitation of these models amongst others, at least for now, is that’re only aware of the data and knowledge at the point where their training took place. This makes them susceptible to incorrect and out-of-date information.
Training new facts into an LLM (RAG vs fine-tuning) Link to heading
Both Fine-tuning and Retrieval Augmented Generation (RAG) are methods mentioned in various resources that can be used to inject / teach new knowledge into an LLM.
In the following chapters I will lay out how I attempted to use both of these approaches to train an LLM on Goodread’s dataset.
Fine-tuning Link to heading
Fine-tuning every parameter in an LLM can be very costly and time consuming to train depending on the size of the model. For comparison, a 7b parameter model (which is one of the smaller LLM model types) can take up to 21-35 hours to be fully fine-tuned given 100,000 training examples. According LLama2’s paper, it took over 184 thousand GPU hours to pre-train the 7b Llama 2 model (See figure below).
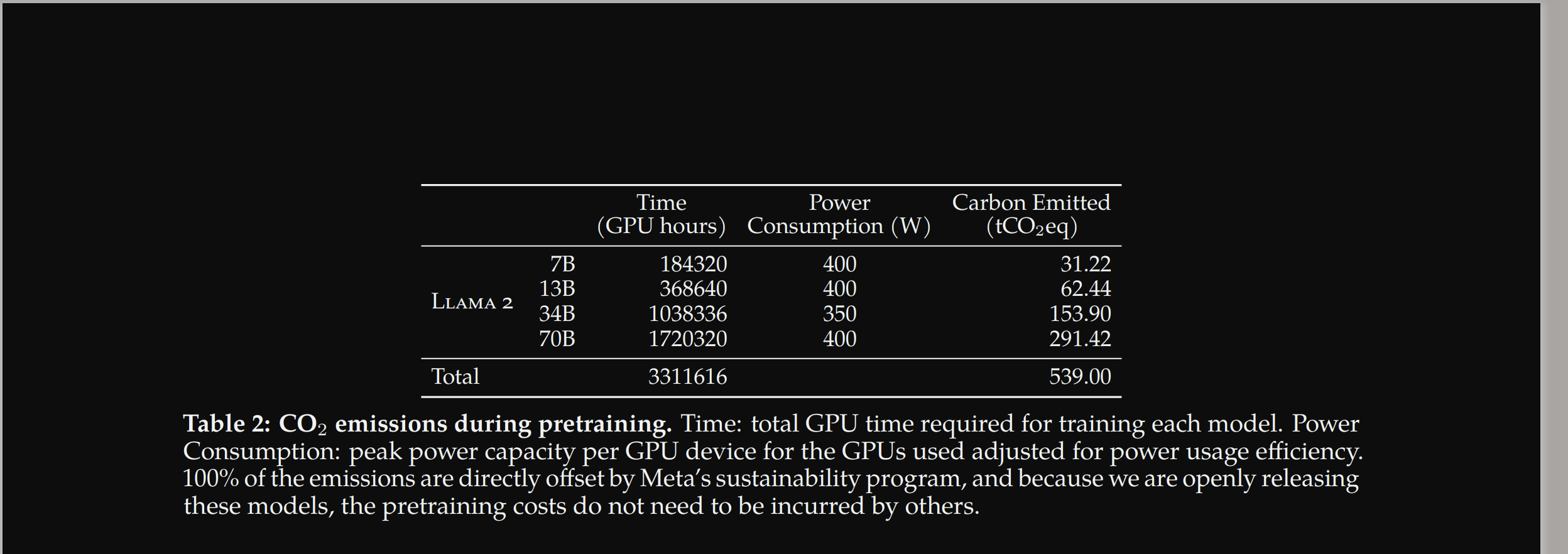
To avoid this high intensity task for every fine-tuning task, a collection of fine-tuning methods called Parameter-Efficient Fine-Tuning or PEFT have been created. PEFT methods only fine-tune a small subset of the full model parameters and have shown to provide comparable performance to full fine-tuning (see the paper here). The most common PEFT method is Low-rank Adaption or Lora, see here.
With this knowledge and after going through a few articles on the subject, I set out to fine-tune Goodreads’ book ratings on the Llama 2 7B model. Llama 2 7B model’s open sourced weights and parameters and it’s relative small size makes it a great candidate for experimenting with this kind of task.
The general steps for fine-tuning a LLM is as follows:
flowchart LR
PrepareData["Prepare Data"] --> PrepareInstructions["Prepare instructions"]
PrepareInstructions --> Trainer("Fine-tune using using Lora")
Trainer --> MergeLoraWithBase("Merge Lora with base Model")
Fine-tuning on Goodread’s data Link to heading
I quickly realised that there aren’t many sources out there explaining how to fine-tune an LLM, specially for custom knowledge. Most articles out there seem to point to a few main sources, one of them being Maxime Labonne’s very well written and informative blog.
It took me a lot longer than I originally thought to complete this task. One of main reasons was that I wasn’t quite sure whether to fine-tune these instructions on a pre-trained model (like the meta-llama/Llama-2-7b-hf) or on a model that’s already been fine-tuned on a large conversation like instructions (like the llama-2-7b-miniguanaco).
To perform the fine-tuning I needed GPUs and one of the places I could find them is from Google colab (I didn’t spend too much time on comparing different providers at this stage as I was really just interesetd in the final model).
I bought 100 compute units from Google Colab which cost me £9.72 at the time of writing. After preparing the notebook for fine-tuning, the whole run took about 10 minutes or 0.8 compute units ((4.82 units per hour / 60) * 10) which at 0.09 pennies a unit comes down to 0.09 * 0.8 = £0.072. This may not seem like much but right now, after a few days of trying to generate a fine-tuned model, my Google Colab dashboard is showing my compute units at 14.78 :).
I’ll go into more details on the dataset in the next chapter.
BTW You can find the final notebook here
Data Preperation + format + instruction preperation Link to heading
As mentioned in the goal, the dataset used to train the model is a collection of data from Goodreads. The instructions used to fine-tune the model is sometimes known as Instruction / Input / Response format which is the format popularised by the Stanford Alpaca project. They demonstrated how they got very good results by taking the Llama 7b and fine-tuned it on 52K instruction-following demostration using this format (see here and here).
Here is the function which given an instruction dictionary, creates a “text” key in the aformensioned format.
def create_prompt_formats(instruction):
INTRO_BLOB = "Below is an instruction that describes a task. Write a response that appropriately completes the request."
INSTRUCTION_KEY = "### Instruction:"
INPUT_KEY = "### Input:"
RESPONSE_KEY = "### Response:"
END_KEY = "### End:"
blurb = f"{INTRO_BLOB}"
instruction_context = f"{INSTRUCTION_KEY}\n{instruction['instruction']}"
input_context = f"{INPUT_KEY}\n{instruction['input']}" if instruction['input'] else None
response = f"{RESPONSE_KEY}\n{instruction['output']}"
end = f"{END_KEY}" + tokenizer.eos_token
parts = [part for part in [blurb, instruction_context, input_context, response, end] if part]
formatted_prompt = "\n\n".join(parts)
instruction["text"] = formatted_prompt
return instruction
A sample instruction looks like this:
{'input': 'Harry Potter and the Half-Blood Prince',
'instruction': "Provide Goodread's website's average rating for the provided book:",
'output': 4.58,
'text': "Below is an instruction that describes a task. Write a response that appropriately completes the request.\n\n### Instruction:\nProvide Goodread's website's average rating for the provided book:\n\n### Input:\nHarry Potter and the Half-Blood Prince\n\n### Response:\n4.58\n\n### End:</s>"}
The instruction is focused on training the model on only a single feature available in the dataset, The average rating of each book.
The instructions then runs through a tokenization process where each word in the “text” block get converted into tokens. For example the above text (“Below is an instruction that….”) when passed through the model’s tokenizer produces the following tokens (input_ids):
{'input_ids': [1, 13866, 338, 385, 15278, 393, 16612, 263, 3414, 29889, 14350, 263, 2933, 393, 7128, 2486, 1614, 2167, 278, 2009, 29889, 13, 13, 2277, 29937, 2799, 4080, 29901, 13, 1184, 29894, 680, 7197, 949, 29915, 29879, 4700, 29915, 29879, 6588, 21700, 363, 278, 4944, 3143, 29901, 13, 13, 2277, 29937, 10567, 29901, 13, 21972, 719, 10173, 357, 322, 278, 28144, 29899, 29933, 417, 397, 10787, 13, 13, 2277, 29937, 13291, 29901, 13, 29946, 29889, 29945, 29947, 13, 13, 2277, 29937, 2796, 29901, 829, 29879, 29958], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
The model is then fine-tuned using the tokens generated in the previous step using the steps described here. I then saved the new fine-tuned model’s weights in this HuggingFace repo.
Fine-tuning Results Link to heading
In order to run inferences on the fine-tuned model and compare the expected vs actual results, I created another notebook in Google Colab.
To generate the model responses for a particular book, I created a generate_response_for_title function.
def generate_response_for_title(model, tokenizer, book_title):
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer, max_length=200)
prompt = f"What is Goodread's website's average rating for {book_title}?"
result = pipe(f"<s>[INST] {prompt} [/INST]")
return result[0]['generated_text']
I then created a function called get_review_from_generated_response that given a book_title and a generated_response from the model, extracts the average score returned from the model, which hopefully it has learned accurately by now.
def get_review_from_generated_response(book_title, generated_response):
pattern = [book_title, "is", "(\d\.\d+)"]
text = " ".join(x for x in pattern)
match = re.search(text, generated_response)
result = None
if match and match.group(1):
result = match.group(1)
return result
I then load Goodread’s data using Panda’s read_csv method and pick out the columns I need:
goodreads_book_details = pd.read_csv(f"{drive_path_dataset}Goodreads_Book_Details.csv")
final_summary = goodreads_book_details[["book_id", "book_title", "genres", "average_rating"]]
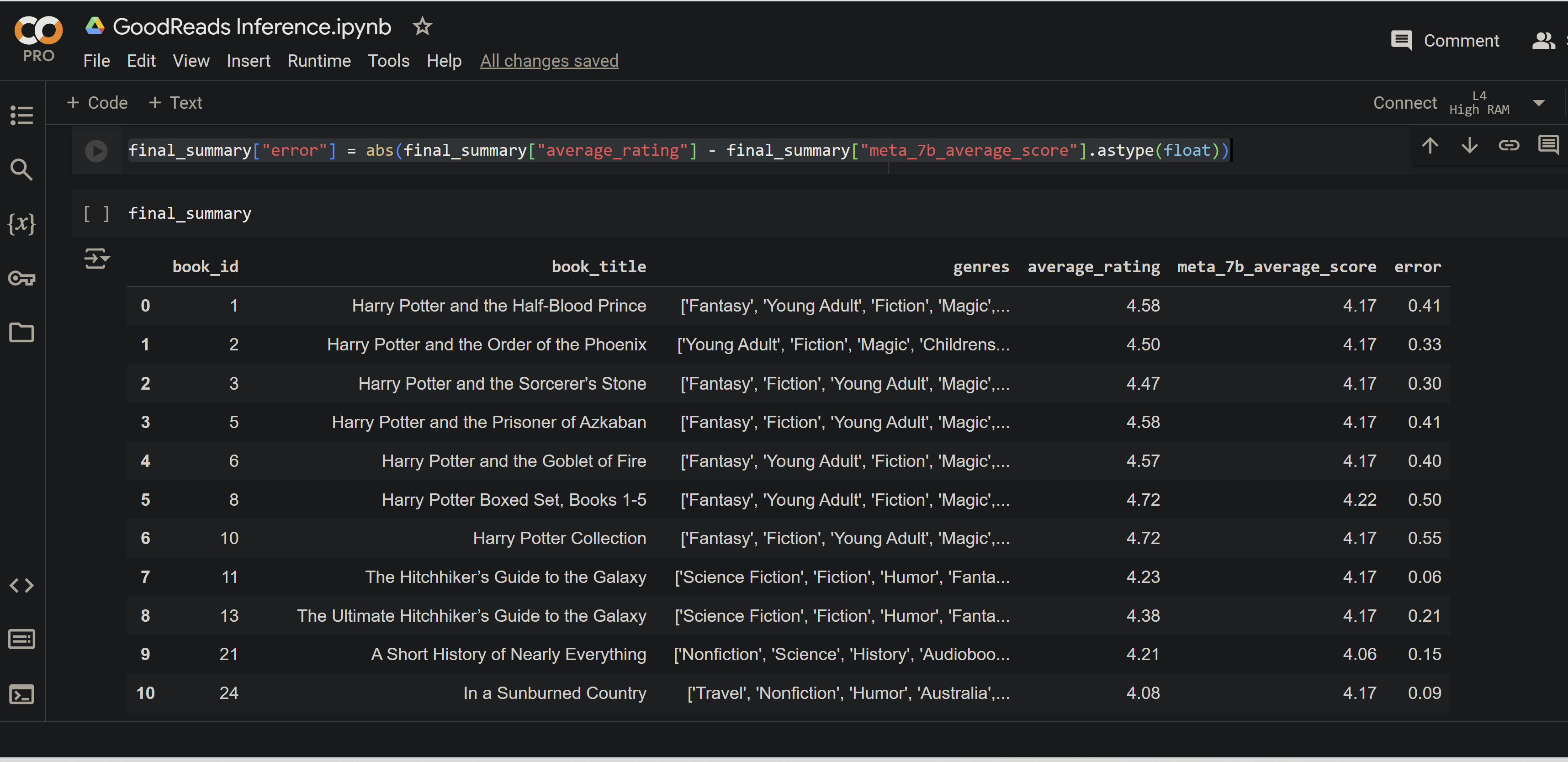
So average_rating holds the original / correct values for each ratings. I then just needed to get the model’s response and compare the two for the books. Using Panda’s apply method this becomes quite easy:
final_summary["meta_7b_average_score"] = final_summary["book_title"].apply(lambda row : get_review_from_generated_response(row, generate_response_for_title(model, tokenizer, row)))
Next I created an error column to calculate the error between the model’s predicted result and the original value.
final_summary["error"] = abs(final_summary["average_rating"] - final_summary["meta_7b_average_score"].astype(float))
Here is a screen grab of the the results:
So now any row for which the error equates to 0 means the model got the result absolutely correctly. Here are the results:
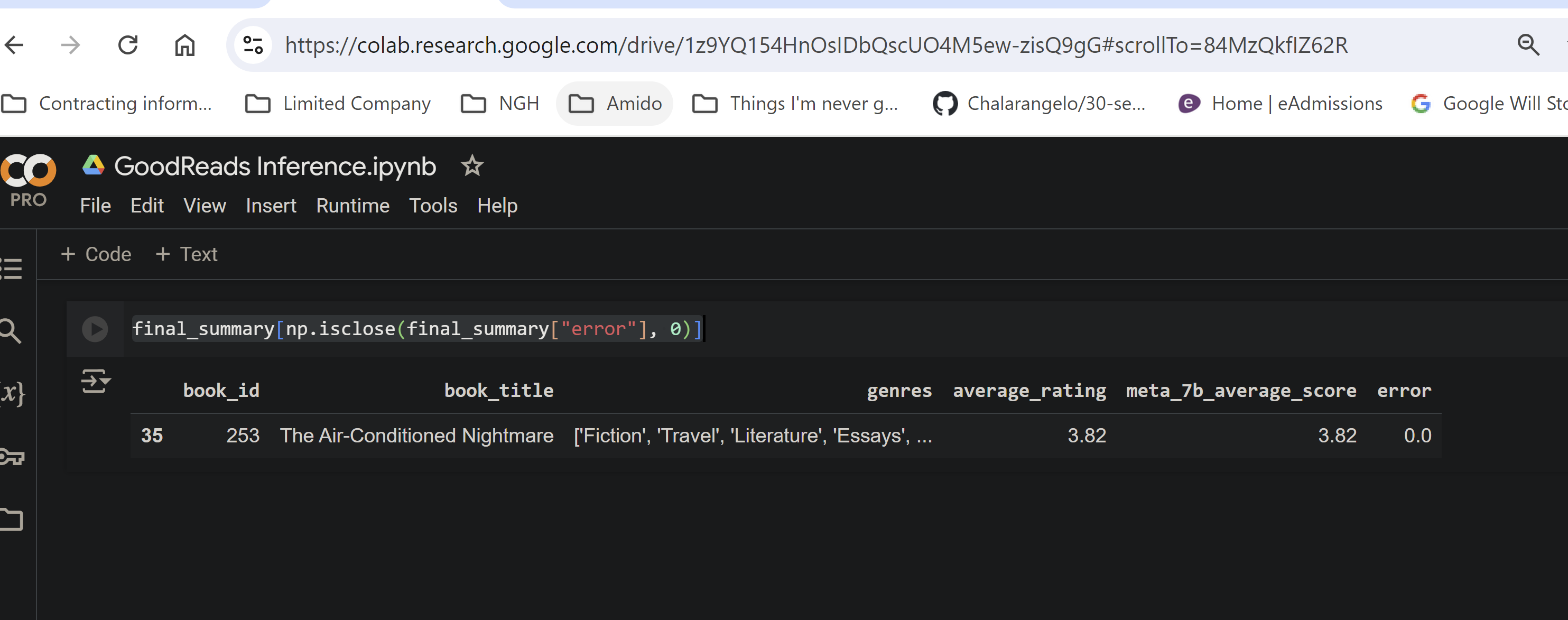
As you can see the model truly learned the average score for only one of the books.
Reflection on Fine-tuning results Link to heading
At this point I was quite confused and didn’t quite understand why the model didn’t pick up and retain the average scores from the instructions at all, specially since I followed quite a few online guides and tutorials that were performing almost exactly the same steps. The model being a language model always returns “a result” but none of them matched the correct one. And for this particular excercise, learning Goodread’s average scores for all the books in their library, the model had to generate a 100% perfect answer every time.
Looking for answers I came across this post on OpenAI’s community forum posted by David Shapiro an independent AI researcher.
Finetuning is for Structure, not Knowledge
According to the post, Finetuning is used to teach chatbots patterns and not knowledge. An example of a pattern is given as a back-and-forth question/answer dialog or the structure of a programming language like Python.
He goes on to explain that LLMs have all the knowledge and they cannot “learn” new “facts” but only structures and patterns.
Retrieval Augmented Generation Link to heading
After failing to achieve my original goal of teaching an LLM model Goodread’s user’s average score for books, I turned my attention to an alternative way of “teaching” facts to LLMs, Retrieval Augmented Generation.
Retrieval Augment Generation or RAG for short is a technique that was initialy introduced in the paper Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. The motivation behind this technique was to add an external memory to LLMs which in turn would address their limited internal memory, give them an ability to revise their knowledge, provide insights into their predictions, and fight “hellucinations”.
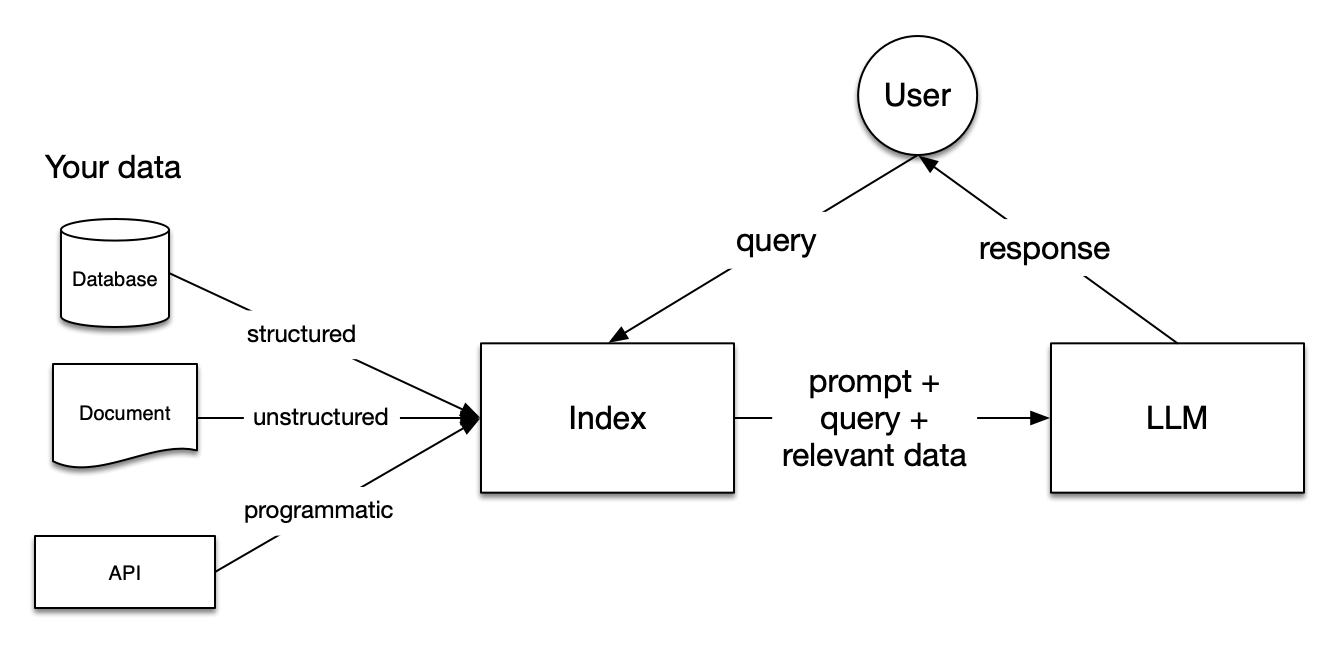
RAG consists of the following components / steps:
- Loading: This involves loading the data (e.g. PDFs, CVs, API responses) into a format for indexing that is easily ingestible for querying.
- Indexing: This means converting the formatted documents into vectors embeddings, so they can be understood by LLMs.
- Storing: Store the indexed data so they don’t have to be reindexed
- Querying: Given the user’s query a Retriever component extracts the relevant data from one or more indexes using one or more strategies. Finally, a specialised prompt (more on this later) + the user’s query + the retrieved data is then fed back into the LLM.
See figure below from LLamaIndex’s high level concept page.
RAG results Link to heading
After going through a few online tutorials, mainly from LlamaIndex’s online guide, I set out to set up a RAG solution using the Goodread’s data mentioned in the goal.
I will go through the main parts with some detail but you can also skip to the final solution here.
There is a whole suite of tools and frameworks that can be levereged to set up a RAG pipeline, but since I gained some familiarity with the LLama 2 LLM I chose LLamaIndex for this excercise.
After installing the requried packages I imported the SimpleDirectoryReader from llama_index.core, created a CSV extractor and pointed them to the directory with the Goodread’s dataset created earlier.
from llama_index.core.prompts.prompts import SimpleInputPrompt
from llama_index.readers.file import CSVReader
parser = CSVReader()
file_extractor = {".csv": parser}
documents_csv = SimpleDirectoryReader(
csvs_path, file_extractor=file_extractor
).load_data()
I then create a system prompt which tells the LLM to essentially not “hellucinate”. This has proved to work quite well with LLama 2 for RAG pipelines:
system_prompt="""
You are a Q&A assistant. Your goal is to answer questions as accurately as possible based on the instructions and context provided.
If you don't know the answer, just say that you don't know. Don't try to make up an answer.
"""
I then create a new instance of the HuggingFaceLLM imported from llama_index huggingface llm package. This along with our embedding_model is set in Llama index’s global Settings object which is what’s used to translate the user’s query to filter out relevant context from the index and pass to the model:
from llama_index.llms.huggingface import HuggingFaceLLM
llm = HuggingFaceLLM(
context_window=4096,
max_new_tokens=256,
generate_kwargs={"temperature": 0.0, "do_sample": False},
system_prompt=system_prompt,
query_wrapper_prompt=query_wrappers_prompt,
tokenizer_name="meta-llama/Llama-2-7b-chat-hf",
model_name="meta-llama/Llama-2-7b-chat-hf",
device_map="auto",
model_kwargs={"torch_dtype": torch.float16, "load_in_8bit": True},
)
embed_model = LangchainEmbedding(HuggingFaceEmbeddings(model_name="sentence-transformers/all-mpnet-base-v2"))
Settings.llm = llm
Settings.embed_model = embed_model
I then created a vector index from the documents_csv object (which was the result of the CSV reader we initiated before) and used the as_query_engine method from LLamaIndex which allows us to essentially query our data.
I then loaded up the goodreads data into a Dataframe using Panda’s read_csv.
goodreads_book_titles = pd.read_csv(f"{csvs}/goodreads_smaller.csv")
df = goodreads_book_titles

I then go through each item in the dataframe, create an instruction using the rating and the title, and add it to an array
updated_documents = []
for index, row in df.iterrows():
updated_documents.append(Document(text=f"average rating for {row['book_title']} is {row['average_rating']}"))
I then create an index using LlamaIndex’s GPTVectorStoreIndex which is a generic way of storing LlamaIndex’s Document objects into an index.
updated_index = GPTVectorStoreIndex(updated_documents)
I then created a few utility functions which would make doing inference and extracting text quicker:
def run_query(book_title, index):
custom_response = index.as_query_engine(llm=llm).query(f"What is the average rating for {book_title}?")
return str(custom_response)
import re
def extract_rating_from_response(response, book_title):
pattern = [book_title, "is", "(\d\.\d+)"]
text = " ".join(x for x in pattern)
match = re.search(text, response)
result = None
if match and match.group(1):
result = match.group(1)
return result
This allows us to run a query on the LLM, using the index we created earlier and extract the score from the response. A sample response looks like:
sample_result = run_query("The Fellowship of the Ring", updated_index)
extract_rating_from_response(str(sample_result), "The Fellowship of the Ring")
Next I wanted to run the query and extract the response from the LLM using the index we created earlier, to the top 50 items in the Goodreads results. Pandas’ fast numpy integration makes this super easy.
goodreads_book_titles["rag_average_score"] = goodreads_book_titles[0:50].apply(lambda x: extract_rating_from_response(run_query(x["book_title"], updated_index), x["book_title"]), axis=1)
Finally I created an error column comparing the actual score (stored in average_rating column) with the RAG score (stored in rag_average_score)
rag_results["error"] = abs(rag_results["average_rating"] - rag_results["rag_average_score"].astype(float))
So now every row that has an error value of 0 indicates that the model correctly “learned” / returned the score.
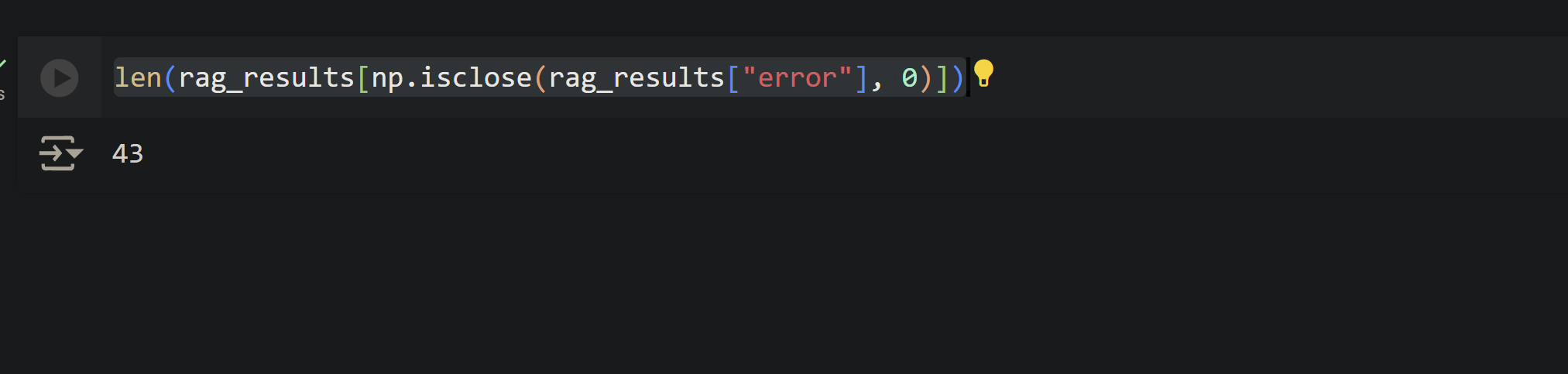
len(rag_results[np.isclose(rag_results["error"], 0)])
The output was: 43. Meaning 43 out of 50 rows were correctly returned. Safe to say major improvement over the fine-tuning attempt.
Cost of running RAG inferences Link to heading
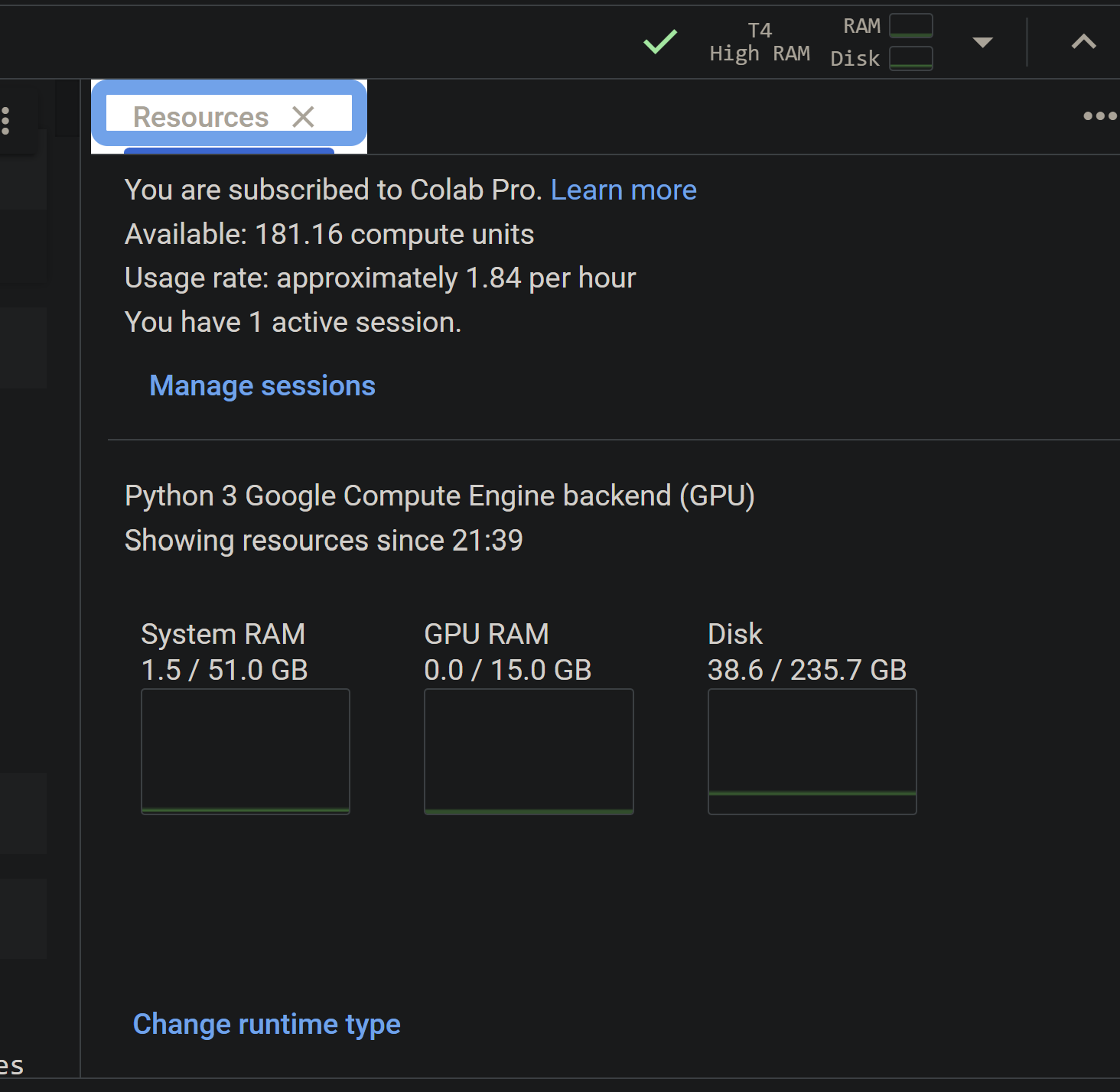
Google Colab shows my usage rate as 1.84 gpu units per hour (see figure) and as we saw earlier the price of a gpu unit is currently 0.0972 pounds per unit.
I also ran a few single queries with the RAG pipeline for a single inference which on average was around 4 seconds. To determine how many gpu units the notebook was using per second I divided 1.84 by 3600 (seconds per hour) which comes to approx 0.0005111 gpu units per second. Finally, 0.0005111 times 4 equals 0.00204.
This means around 1000 inferences equals 2.04 gpu units or 0.2 pounds.
1,000 * 0.00204 * 0.097 = 0.19 pounds
RAG inferences 10,000 * (0.00204) * 0.097 gpu unit price = 1.9 pounds
Conclusion Link to heading
In this post I set out to learn about the latest advancements in AI technologies by actually implementing something basic but useful. Writing this article helped me demistify some of the genAI concepts and I even found a way to be able to run them relatively cheaply using Google Colab.
I do see that beyond the usefullness of general chatbots, one of the more practical applications of LLMs will be to train them on custom user data. This can be currently achieved using RAG and language models with very large context windows like the Anthropic’s Claude 3, with 200K tokens.
Next I would like to experiment with hosting an LLM with a RAG pipeline that can be accessed by actual users on a large scale. Some of the services that seem interesting for this use case are replicate and Amazon Bedrock.
What could also be interesting is a RAG pipeline that can learn from user feedback. For instance maybe a chatbot that can be used to talk about a product in an online shopping website and respond with what people are saying about it in the comments. And as mornewe comments are added, the RAG pipeline can pick them up and run them for new inferences.